
What is Unstructured Data?
In this era of applications generating too much of data (sometime referred to as BigData) and data driven business paradigm shift, it’s imperative to consume all types of data available at various channels. Some of these data coming from very legitimate sources like our own applications (e.g. transactions) which is well known in terms of their predefined structures and their use cases but with the advent of Machine Learning & immense infrastructure capabilities, it has also become of business interests to grasp whatever information in whatever shape is available to derive important decisions and to stay ahead of the competition.
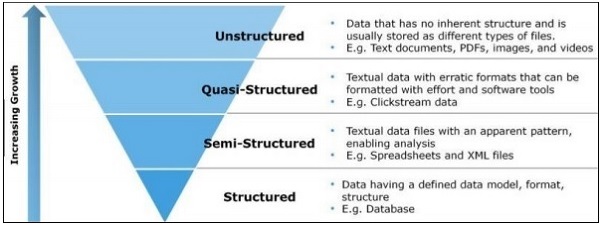
Unstructured data is something which is NOT structured in terms its schema e.g. social media comments / posts, emails, phone call transcriptions, IoT information, log files (semi-structured) etc. i.e. more of textual forms which doesn’t really fit into relational databases as they don’t have fixed formats and are of large sizes generally. This needs special treatment not just only to process them but also to efficiently store them so that you can easily read them out for analytical purposes later.
Broadly these can be categorized as
- Human-generated unstructured data
Email, mobile data, social media, log files etc.
- Machine-generated unstructured data
Sensors data, scientific exploratory data, digital surveillance data etc.
Semi-structured Data
There is also some data files which cannot either be termed as fully structured as they don’t comply with formal schema /models nor fully unstructured as they have got some sort of tags / markers to help identifying / extracting elements of the same. This is known as Semi-Structured data e.g. JSON & XML files which enforce some hierarchies of records within.
Below pictures categories these data formats and shows their increasing volume with time:
Why we need to deal with unstructured data?
Unstructured data was already there in some capacity, although it has increased enormously with emergence of high tech data sources like social media, internet devices etc. and supported by cheaper & advanced storage platforms.
Since, 80% of the data in industries is unstructured; organizations need to have right capabilities to know how to deal with it and make most out of it. Over the period of time, this has transformed from an additional advantage to know your unstructured data to a necessity to stay competitive.
Proper data management strategies and architecture of handling unstructured data along with structured data should help in driving profitable business by means of providing valuable analytical insights hidden into these data extracts.Also, NOSQL kind of DB stores allow to quickly make use of these (semi) structured data documents to respond to operational queries.
Data is known as new currency these days, hence even if organization is not ready enough to invest into processing of these huge unstructured data consumption, one should atleast be storing them for futuristic purposes.
How to consume unstructured data –data ingestion & storage?
As stated above there are a variety of such unstructured data sources with varying formats, volume and nature (streaming, batched etc.) and moreover there are chances that these sources are not readily available to publish it effectively to be consumed.
With all these complexities, there can be multiple different adapters to be used to consume them & differently store them based upon their nature. We’ll go through the exact technical implementation of some of these per use cases in next article, but here we’ll look at some of these categorical data types and how these can be captured into our Data Lake / store at high level.
Some of these adapters are pretty much the same which we can utilize for consuming structured data as well. For example, in case of streaming data, irrespective of whether it’s structure, semi-structured or full unstructured we need a data pipeline (built into tools like Apache Beam, Apache Flink, Spark etc.) which should be capable enough to hook into those high frequency of data flow. Thereafter, depending upon whether we want to really transform them before they can be stored or not, further components may vary.
Similarly depending upon volume of the data, we might need to store them into Hadoop (HDFS) kind of storage or NOSQL kind of database, essentially flowing down into a Data Lake (would be discussed in details in next article).
Let’s now look at some scenario based unstructured data sources, their availability and how to hook into to ingest them into data lake.
- Log / content files (mix of structured & unstructured data)
This category of data contains files like application / transactional logs which are captured during the course of application functioning and are generated in terms of huge data files containing application as well as system information logged. Part of these is structured data like info/ warning/ errors, some urls, connection details etc. but other part includes completely unstructured data which can vary in length & size.
A basic pipeline for this could be as below:

CDC (change data capture tool which can sense the changes and fetch those logs from system not capable enough to produce these log files by themselves).
Apache Kafka (to receive those message in a manageable way if they are huge in numbers).
Connector (can be provided by storage system or some third party provider).
NOSQL / HDFS (depending upon if they are structured enough to do some analysis storing them into NOSQL (MongoDB etc.) or needs further processing storing them into HDFS for Hadoop).
- Fully unstructured / big data file
This is free styled data files like from social media comments, images, audio files, video files etc. which are mostly of huge size and are to be processed using specialized tools for any analytical purposes.
Depending upon the source of these data files, these can be just copied into the unstructured data store.
A basic pipeline for this could be as below:
Either this can be directly stored into HDFS or to be converted into serialized version (into binary files i.e. sequence files) based upon the requirement e.g. f we want to do some custom image processing on top of the binary files or to store & use images directly.
Below simple command will fetch this and store it into HDFS / Hadoop
bin/hadoop fs -put /src_image_file /dst_image_file
So, practically anything which can be converted into bytes can be stored into HDFS (images, videos etc)
- Semi-structured / structured unstructured
As mentioned above, certain unstructured files which have certain hierarchical structure in terms of tags & elements include XML, JSON files etc. These can be mapped to RDBMS database tables as well but needs some Xquery or special treatment before it can be stored. On the other hand, these can also be directly stored without worrying about their changing schema into NOSQL databases like MongoDB which supports transactions & SQL queries.

There are some third party tools/ adaptors available which can provide a unified data ingestion layer with multiple connectors (ranging from document repositories, file systems, sharepoint, message queues, databases etc.).
E.g. Aspire Connector framework for Hadoop which can not only consume the data but can also help extracting metadata along with. Another wrapper provided by Confluent for Kafka to connect to MongoDB to insert de-serialized messages into.
How this stored semi/un structured data files can be queried or used in analytical reporting purposes will be discussed in next articles.
